OpenMP并行程序设计——for循环并行化详解
OpenMP并行程序设计——for循环并行化详解
并发系统分为两种:
- 共享内存系统:各个核可以共享访问计算机的内存。
- 分布式内存系统:每个核都有自己独立私有的内存,核之间的通信需要通过网络发送消息。
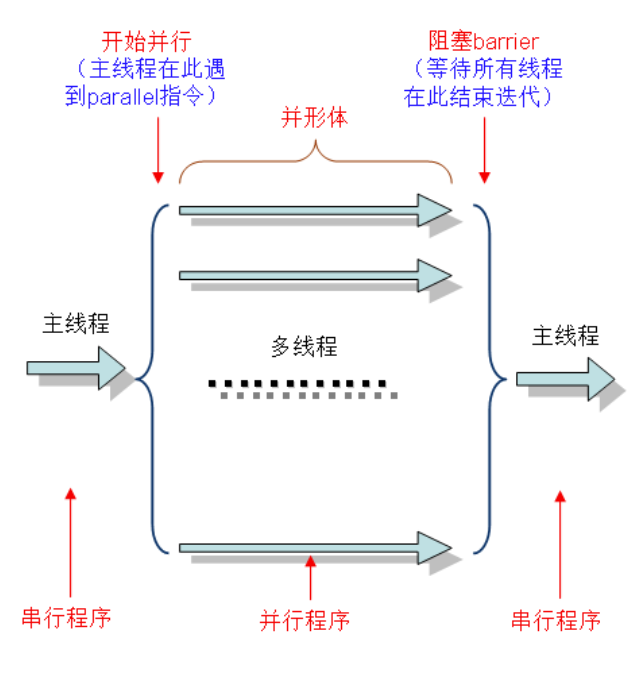
首先,如何使一段代码并行处理呢?omp中使用parallel制导指令标识代码中的并行段,形式为:
#pragma omp parallel
{
每个线程都会执行大括号里的代码
}
#include <iostream>
#include "omp.h"
using namespace std;
int main(int argc, char **argv) {
//设置线程数,一般设置的线程数不超过CPU核心数,这里开4个线程执行并行代码段
omp_set_num_threads(4);
#pragma omp parallel
{
cout << "Hello" << ", I am Thread " << omp_get_thread_num() << endl;
}
}
带有for的制导指令:
for制导语句是将for循环分配给各个线程执行,这里要求数据不存在依赖。
使用形式为:
(1)#pragma omp parallel for
for()
(2)#pragma omp parallel
{//注意:大括号必须要另起一行
#pragma omp for
for()
}
注意:第二种形式中并行块里面不要再出现parallel制导指令,比如写成这样就不可以:
#pragma omp parallel
{
#pragma omp parallel for
for()
}
第一种形式作用域只是紧跟着的那个for循环,而第二种形式在整个并行块中可以出现多个for制导指令。下面结合例子程序讲解for循环并行化需要注意的地方。
假如不使用for制导语句,而直接在for循环前使用parallel语句:(为了使输出不出现混乱,这里使用printf代替cout)
#include <iostream>
#include <stdio.h>
#include "omp.h"
using namespace std;
int main(int argc, char **argv) {
//设置线程数,一般设置的线程数不超过CPU核心数,这里开4个线程执行并行代码段
omp_set_num_threads(4);
#pragma omp parallel
for (int i = 0; i < 2; i++)
//cout << "i = " << i << ", I am Thread " << omp_get_thread_num() << endl;
printf("i = %d, I am Thread %d\n", i, omp_get_thread_num());
}
从输出结果可以看到,如果不使用for制导语句,则每个线程都执行整个for循环。所以,使用for制导语句将for循环拆分开来尽可能平均地分配到各个线程执行。将并行代码改成这样之后:
#pragma omp parallel for
for (int i = 0; i < 6; i++)
printf("i = %d, I am Thread %d\n", i, omp_get_thread_num());
点赞